
『かなこん (Glaeja Ext.)』は、『Glaeja』のテキストレイヤー等で「1バイトかなフォント」を用いて表示させるための文字コード変換をおこなうエクステンションです。
インストールと簡単な使い方の解説は以下に記します。
インストール
『かなこん』の最新版は「ver. 1.0.0 (2016-05-06)」です。下のアイコンをクリックするとPlayストアにジャンプしますので、そこからインストールしてください。
インストール後は、ドロワーから『Glaeja』を起動し、[データ管理]→[エクステンションの管理]に進み、[新規登録]ボタンをクリックして『かなこん』を登録してください。
また、『かなこん』をバージョンアップや再インストールした場合には、一度ドロワーから『Glaeja』を起動して[データ管理]→[エクステンションの管理]を開いてください。この画面を開いたタイミングで、『かなこん』の初期化がおこなわれるためです。
「GEXコード」の初期値は“GEX_KANA”ですが、お好みで変更しても構いません。
アイテム欄右端の設定アイコンをクリックするか、ドロワーから起動すると、『かなこん』のアバウト画面を開くことができます。
アバウト画面
『かなこん』には設定する項目がありません。この画面にはバージョンと簡単なヘルプだけが表示されます。

『Glaeja』上での使い方
基本的な使い方
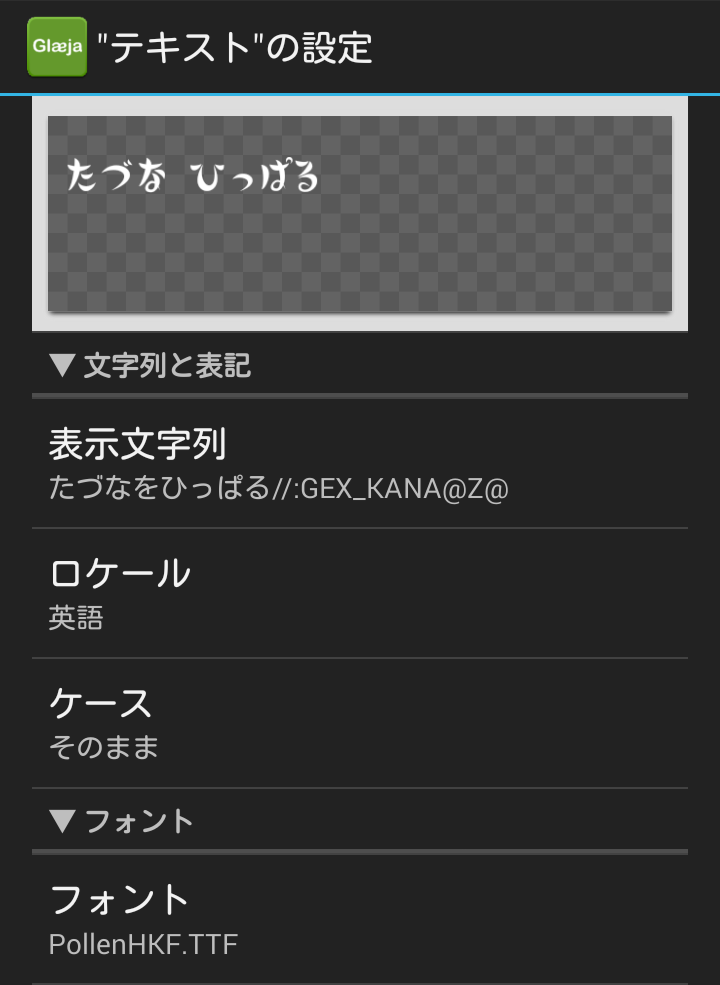
『Glaeja』のテキストレイヤー等の表示文字列において、以下の様に記述します。
- 変換対象文字列//:GEX_KANA@.../.../\Z@
要するに、1バイトかなフォントで表示させたい文字列の末尾に「//:GEX_KANA@.../.../\Z@」を追加して、『かなこん』を呼び出すだけです。

上記作例では「フォントファウンドリー・イアイ・ジェイピー」の「Pollen」を使いました
表示させたい文字列の末尾には、必ず「//」を追加してください。追加しなかった場合、文字列が全て表示されないか、文字列中の「/」より左側のみが化けた状態で表示されてしまいます。
1バイトかなフォントによる表示の仕組み
1バイトかなフォントとは、2バイト日本語フォントやマルチバイト多言語フォントが作られる前に使われていた、かな文字用のフォントです。1バイトで表現できる文字数が256文字しかないため、通常はかな文字と一部記号しか含まれておらず、英数字などの1バイト文字コードに対してかな文字の字形を表示するように割り当てられています。
要するに、文字列中に「3 (半角数字のサン)」の文字コードがあれば「あ (かなのア)」を表示し、「e (半角英小文字のイー)」の文字コードがあれば「い (かなのイ)」を表示する、というように字形を表示します。かなのうち、ひらがなが表示されるかカタカナが表示されるかはフォントによって異なり、「ひらがな専用の1バイトかなフォント」と「カタカナ専用の1バイトかなフォント」が存在しています。
Androidでは、テキストのコード表現にマルチバイトであるUnicode (UTF-8)が用いられており、「あ (かなのア)」は「\xE3 \x81 \x82」という3バイトの文字コードで表されています。これを1バイトかなフォントの字形で表示するためには、テキスト中の全ての「\xE3 \x81 \x82」という3バイトを、「\x33」という「3 (半角数字のサン)」という1バイトのコードに変換してやればよいのです。他のかな文字や記号についても同様に変換してやる必要があります。
つまり、「あんどろいど」と1バイトかなフォントで表示させるためには、文字列を「3yS_eS」に変換してやればよいことになります。

この変換を自動でおこなうためのエクステンションが『かなこん』です。『かなこん』は、与えられた変換対象文字列のうちのかな文字と一部記号(約物)について、その全てを1バイトかなフォント用に文字コード変換をおこないます。
『かなこん』では、以下の対応表に従って文字コードの変換をおこなっています。

『かなこん』は、上記対応表にない文字は変換しないので、漢字などは元のUTF-8文字コードがそのまま戻ってきます。多くのAndroid端末では、1バイトかなフォントに含まれていない文字コードは「端末のデフォルトフォント」で表示されるようになっています。

変換モードスイッチ
変換対象文字列の末尾に追加する「//」と「:GEX_KANA」の間には変換モードを変更するスイッチを記述することができます。
- 変換対象文字列//[hks]:GEX_KANA@.../.../\Z@
スイッチとして「h」が記述されていると、変換対象文字列のうちの「ひらがな」のみが文字コード変換されます。
スイッチとして「k」が記述されていると、変換対象文字列のうちの「カタカナ」のみが文字コード変換されます。
スイッチとして「s」が記述されていると、変換対象文字列のうちの「約物」のみが文字コード変換されます。
また、スイッチが一切記述されていない空文字列の場合、「hks」であると見なされます。

上記例で、指定しなかったほうのかな文字の文字コードが変換されず、それが1バイトかなフォントに含まれていないため、デフォルトフォントで表示されていることに注意してください。
また、例で用いている1バイトかなフォントは「ひらがな専用」であるため、カタカナを変換した結果がひらがな字形で表示されていることにも注意してください。つまり、1バイトかなフォントでは「ひらがなカタナカ交じり文」は表示できないのです。
優先変換文字列
まず、以下の2つの作例を見てください。

左側は「Pollen」で表示させたものですが、「を」が表示されていません。
また、右側は「ガウプラ」の「クサナギ」というカタカナ専用1バイトかなフォントで表示させたものですが、こちらでは「づ」「を」「っ (促音のツ)」が異なる字形で表示されてしまっています。
これは、これらの字形に対応する文字コードが『かなこん』の持つ変換表と異なるコードになっているためです。
どの字形をどの文字コードに割り当てるかという対応は、「JIS X 6002」という規格に準拠して決められているのですが、この規格では「並み仮名(清音)」「捨て仮名(拗促音)」「約物」しか定められていません。ですので、「並み仮名(濁音・半濁音)」に割り当てられている文字コードはフォントによって異なるものがあります。また、「JIS X 6002」は「表示する字形」と「押下するキー」の対応を定めた規格であって、「文字コード」 は未定義です。そのため、「を」「っ (促音のツ)」などの対応文字コードもフォントによって異なるものがあります。
ですので、『かなこん』の変換表と異なる文字コードになっているフォントでは、上記例のように表示が化けてしまいます。
このようなフォントで意図したように表示させるためには、変換対象文字列の末尾に追加する「//」の間に「優先変換文字列」を記述する必要があります。
優先変換文字列は、以下のように記述します。
- 変換対象文字列/(元文字1)(置換文字1)(元文字2)(置換文字2).../:GEX_KANA@.../.../\Z@
上記のように、2つの「/」の間に「変換したい元の文字」と「どの文字コードに置換するか」を並べて記述します。
例えば、「Pollen」では「を」は「! (半角記号のエクスクラメーションマーク)」に割り当てられていますので、以下のように優先文字列を記述すれば正しく表示されます(「!」がGlaejaの「電波情報エスケープキャラクタ」と認識されないよう「' (単一引用符)」で囲まれていることに注意)。

また、「クサナギ」では「づ → Z (英大文字ゼット)」「を → ! (半角記号のエクスクラメーションマーク)」「っ → Y (英大文字ワイ)」に割り当てられていますので、こちらは以下のように優先文字列を記述すれば正しく表示されます。

フォントごとの字形と文字コードの対応表は、フォント配布サイトや配布パッケージに記載されていることが多いです。また、Windowsであればインストールして『文字コード表』というアプリで確認することもできます。

また、Windows上でフォントファイルをダブルクリックした際に表示されるフォント確認画面の、下図赤枠で囲った部分は、
abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ
1234567890.:,;'"(!?)+-*/=
の順になっていますので、そこから確認することも可能です。

応用的な使い方
半角英数字交じり文を表示する
1バイトかなフォントでは、半角英数字や記号などの1バイト文字コードを対応するかな文字として表示します。『かなこん』は、Androidで使われているUTF-8マルチバイト文字コードのなかからかな文字を探しだして、1バイトかなフォントで表示するために1バイト文字コードに変換します。このため「元々のUTF-8で表された文字列のなかに半角英数字や記号などがあった場合、それが意図せずかな文字として表示されてしまう」ことになります。
例えば、「じこくは$HH:mm$です。」を1バイトかなフォントで表示させようとすると、以下の様に時刻部分が化けてしまいます。

「じこくは$HH:mm$です。」の時刻部分(上記例では“15:33”)の半角数字が1バイトかなフォントでかな文字として表示されてしまっているわけです。
こうした場合にはリッチテキストレイヤーを使います。リッチテキストなら文字列中に複数のフォントを混在できますので、かな文字部分と半角英数字を異なる文字列に分割しフォントを分けることが可能です。

その他
注意
一部機種や環境では、そもそも1バイトかなフォントが表示できないものがあることが確認されています。
下図左側は「Xperia™ Z1 f (OS 4.4.2)」上の『Glaeja』で、フォント選択ダイアログ上で“The quick brown fox ...”が1バイトかなフォントである「GauFontKusanagi.TTF」で表示されています。
それに対し、右側「Androidエミュレータ (OS 5.0.1)」では同じフォントがデフォルトフォントに置き換わって表示されてしまっています。このような場合には、「かなこん」使用の有無に関わらず、申し訳ありませんが環境として1バイトかなフォントが表示できません。

OSSライセンス
『かなこん』は以下のオープンソース・ソフトウェアを利用しています。
○ GlaejaExtension_v100.jar
Copyright (c) 2014 kanitawa
ライブラリJar“GlaejaExtension_v100.jar”は、MITライセンスのもと公開されています。
http://opensource.org/licenses/mit-license.php
既知の不具合
- ver.1.0.0では、特に報告されていません。
更新履歴
- 『かなこん』
- ver.1.0.0 (2016-05-06):ストア公開
以上
0 件のコメント:
コメントを投稿